Matlab中fscanf的用法
今天读一段程序,主要目的是从一个文件中读取数据,然后用这些数据来画图。
matlab中的fscanf的用法如下:
A=fscanf(fid,format)
[A, count]=fscanf(fid,format,size)
[A, count]=fscanf(fid,format,size)
个人感觉用的最多的是 这样的形式:
data = fscanf(fid,format,size);
期中data为读取内容的数组,他的大小由size决定。size是一个[m n]的向量,
m为行,n为列(注意,这里读取的顺序是按列优先排列的,不明白的话可以看
下面的例子),若n取inf表示读到文件末尾。fid为fopen打开文件的返回值,
format是格式化参数(像printf、scanf)。
举个小例子:
路径+文件名:d:\moon.txt
内容:13,1,3.4
3,2.1,23
1,12,2
4,5.4,6
现在为了读取moon中的数据存在一个数组里,可以用如下方法
fid=fopen('d:\moon.txt');
data_1 =fscanf(fid,'%f,%f,%f',[3,inf]) ;%这里得用单引号
data_2 =fscanf(fid,'%f,%f,%f',[2,inf])
data_3 =fscanf(fid,'%f,%f,%f',[2,2])
fclose(fid);
这时data_1, data_2, data_3分别是一个数组,其内容分别如下:
data_1
13 3 1 4
1 2.1 12 5.4
4 23 2 6
data_2
13 3.4 2.1 1 2 4
1 3 23 12 4,5 6
data_3
13 3.4
1 3
由此可见,读数据的时候,从多维数组的水平方向,一个一个读取,传递给新的数组时,从列方向优先。
Matlab runtime运行时间计算
通常在算法研究中要对比算法的效率。比较算法效率的一种重要指标,就是考量不同算法在计算处理相同规模的实验数据时,需要的计算时间。本文在这里罗列三种常见的matlab 程序运行时间计算方法。
当然这个对于只有几秒钟的小程序没有什么意义,但是对于大程序就有很重要的意义了。
注意:三种方法由于使用原理不一样,得到结果可能有一定的差距!
1、tic和toc组合(使用最多的)
计算tic和toc之间那段程序之间的运行时间,它的经典格式为
- tic
- 。。。。。。。。。。
- toc
复制代码
换句话说程序,程序遇到tic时Matlab自动开始计时,运行到toc时自动计算此时与最近一次tic之间的时间。这个有点拗口,下面我们举个例子说明
- % by dynamic of Matlab技术论坛
- % see also http://www.matlabsky.com
- % contact me matlabsky@gmail.com
- % 2009-08-18 12:08:47
- clc
- tic;%tic1
- t1=clock;
- for i=1:3
- tic ;%tic2
- t2=clock;
- pause(3*rand)
- %计算到上一次遇到tic的时间,换句话说就是每次循环的时间
- disp(['toc计算第',num2str(i),'次循环运行时间:',num2str(toc)]);
- %计算每次循环的时间
- disp(['etime计算第',num2str(i),'次循环运行时间:',num2str(etime(clock,t2))]);
- %计算程序总共的运行时间
- disp(['etime计算程序从开始到现在运行的时间:',num2str(etime(clock,t1))]);
- disp('======================================')
- end
- %计算此时到tic2的时间,由于最后一次遇到tic是在for循环的i=3时,所以计算的是最后一次循环的时间
- disp(['toc计算最后一次循环运行时间',num2str(toc)])
- disp(['etime程序总运行时间:',num2str(etime(clock,t1))]);
复制代码
运行结果如下,大家可以自己分析下
- toc计算第1次循环运行时间:2.5628
- etime计算第1次循环运行时间:2.562
- etime计算程序从开始到现在运行的时间:2.562
- ======================================
- toc计算第2次循环运行时间:2.8108
- etime计算第2次循环运行时间:2.813
- etime计算程序从开始到现在运行的时间:5.375
- ======================================
- toc计算第3次循环运行时间:2.0462
- etime计算第3次循环运行时间:2.046
- etime计算程序从开始到现在运行的时间:7.421
- ======================================
- toc计算最后一次循环运行时间2.0479
- etime程序总运行时间:7.421
复制代码
2、etime(t1,t2)并和clock配合
来计算t1,t2之间的时间差,它是通过调用windows系统的时钟进行时间差计算得到运行时间的,应用的形式
- t1=clock;
- 。。。。。。。。。。。
- t2=clock;
- etime(t2,t1)
复制代码
至于例子我就不举了,因为在上面的例子中使用了etime函数了
3、cputime函数来完成
使用方法和etime相似,只是这个是使用cpu的主频计算的,和前面原理不同,使用格式如下
- t0=cputime
- 。。。。。。。。。。。。。
- t1=cputime-t0
复制代码
上面说到了三种方法,都是可以进行程序运行时间计算的,但是Matlab官方推荐使用tic/toc组合,When timing the duration of an event, use the tic and toc functions instead of clock or etime.
至于大家可以根据自己的喜好自己选择,但是使用tic/toc的时候一定要注意,toc计算的是与最后一次运行的tic之间的时间,不是第一个tic,更不是第二个。。。。。
Matlab 稀疏矩阵存储与处理
本文介绍Matlab 在稀疏矩阵存储与处理方面的主要函数,并以实例说明
Matlab Legend插入部分图形句柄
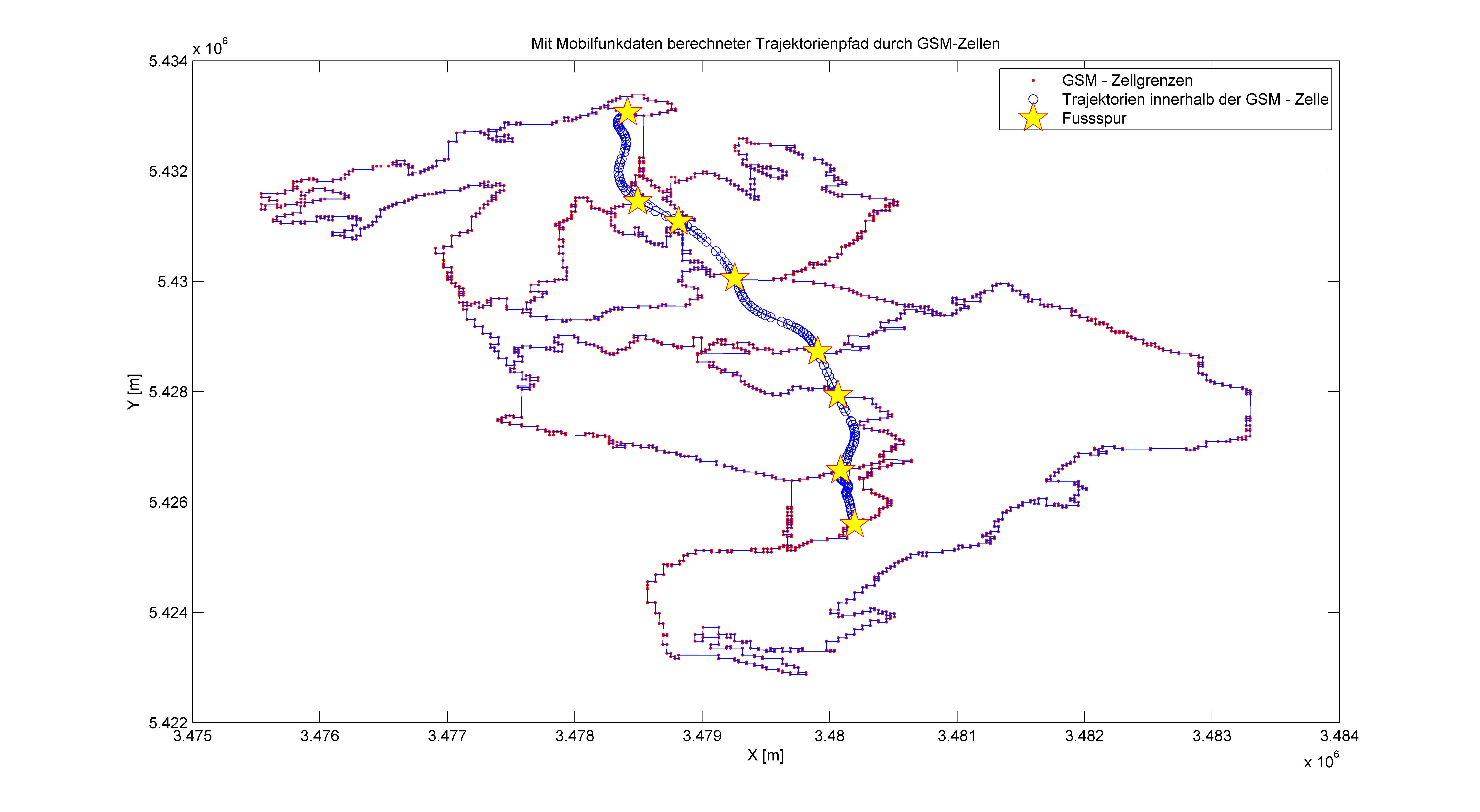
摘要:
由于之前有一个安排上的错误,使用Matlab绘图时采用的,输出数据立即绘制到图形上。以至于在使用Legend插入图例时,插入了上千个图例,其中图形相同的图例重复。
通过其他软件(如PPT)去额外添加图例,又不能得到比较高质量DPI的图片。
受下面的程序所启发,通过Legend本身作文章,解决了问题。
b = bar(rand(10,5),'stacked'); colormap(summer); hold on
x = plot(1:10,5*rand(10,1),'marker','square','markersize',12,...
'markeredgecolor','y','markerfacecolor',[.6 0 .6], 'linestyle','-','color','r','linewidth',2);
hold off;
legend([b,x],'Carrots','Peas','Peppers','Green Beans', 'Cucumbers','Eggplant');
通过图例能得知,legend 函数可以以需要作为图例的函数作为输入,如图中的[b,x]就是需要作为图例的函数。
其中,b,x都是图形句柄(这是Matlab的图形表达)。
笔者的解决方法是:
把需要作为图例而绘制的函数,选择其中一个(一般选择第一个,或者最后一个,以便于循环处理),并以句柄表明(如下面程序中的GSM_cell_boundary, stra_Tra, fp_Star )。
% extract the samples of legend elements above
legend_main = [GSM_cell_boundary, stra_Tra, fp_Star]
xlabel(xlabel_text)
ylabel(ylabel_text)
title(title_text)
legend(legend_main, 'GSM - Zellgrenzen','Trajektorien innerhalb der GSM - Zelle','Fussspur', 'Location','NorthEast');
% legend(legend_main, 'Boundary of the GSM Cell','Part of trajectory in the GSM Cell','Footprint', 'Location','NorthEast');
然后使用Legend的常规方法,绘制图例即可。
仍有不明白之处,请Email: shchen.lmars@live.cn
Understanding elements in MATLAB 理解Matlab
这里不讲Matlab的历史沿革,不讲Matlab的基础语法,仅仅从一些数据结构来谈谈Matlab编程思路。
看来对基础的
cell
vector
matrix
string 还不够区分出来
Matlab 函数之strfind, regexp
strfind用法 规定第二个参数类型只能是向量 不可以是cell 。
Syntax
- start = regexp(str,expr)
- [start,finish] = regexp(str,expr)
- [start,finish,tokens] = regexp(str,expr)
- [...] = regexp(str,expr,'once')
Description
start = regexp(str,expr) 返回一个向量,元素分别是表达式expr在字符串Str中的位置。表达式可以是:'c[aeiou]+t' (cat,caet, caoueouat)
当Str或者expr 是个元胞字符数组,regexp 返回 m-by-n元胞数组,其元素是向量,其中M是Str该字符串的指数,
http://www.weizmann.ac.il/matlab/techdoc/ref/regexp.html
数组里面的字符串轮流查找。
1从一组字符串里面,
string1={'42_time[ ]_', 'speed_vel', '002_air', 'water_005', 'att059[ ]', '895dps'}
查找下面几个字符串,
string0={'time', 'air','water'}
并且给出它们所在的列数。
*time 返回1
*air 返回3
*water 返回4
唉 看到cell就知道又是麻烦....
-
string1={'42_time[ ]_', 'speed_vel', '002_air', 'water_005', 'att059[ ]', '895dps'}
string0={'time', 'air','water'}; - for i=1:size(string0,2)
- s=regexp(string1,string0(i));
- weizhi=find(cellfun('isempty',s)==0);
- disp([weizhi string1(weizhi)])
- end
[1] '42_time[ ]_'
[3] '002_air'
[4] 'water_005'
- string1={'42_time[ ]_' ,'speed_vel' ,'002_air', 'water_005','att059[ ]','895dps'}
- string0={'time','air','water'}
- string1={'42_time[ ]_' ,'speed_vel' ,'002_air', 'water_005','att059[ ]','895dps'};
- string0={'time', 'air','water'};
- for i=1:size(string0,2)
- s=strfind(string1,string0{i});
- weizhi=find(cellfun('isempty',s)==0);
- disp([weizhi string1(weizhi)])
- end
注意string0{i}
结果一致
- [1] '42_time[ ]_'
- [3] '002_air'
- [4] 'water_005'
也可以用匿名函数
- string1={'42_time[ ]_' ,'speed_vel' ,'002_air', 'water_005','att059[ ]','895dps'};
- string0={'time', 'air','water'};
- f=@(x)find(~cellfun(@isempty,strfind(string1,x{:})));
- arrayfun(f,string0)
ans = 1 3 4
稍作修改:
- string1={'42_time[ ]_' ,'speed_vel' ,'002_air', 'water_005','att059[ ]','895dps'};
- string0={'time', 'air','water'};
- f=@(x)find(~cellfun(@isempty,strfind(string1,x))); % 将x{:}直接修改为x
- cellfun(f,string0) % 此时需要将arrayfun修改为cellfun
arrayfun和cellfun果然是强大啊
Matlab 随机数 小结
1,rand 生成均匀分布的伪随机数。分布在(0~1)之间
2,randn 生成标准正态分布的伪随机数(均值为0,方差为1)
3, randi 生成均匀分布的伪随机整数
如我的matlab在打开时输入以下命令将得到相同的随机数:
>> randn(3)
ans =
>> randn(3)
ans =
>> randn(3)
ans =
normrnd是自己可以指定均数和标准差的正态分布。
另外,Matlab随机数生成函数主要包括:
betarnd 贝塔分布的随机数生成器
binornd 二项分布的随机数生成器
chi2rnd 卡方分布的随机数生成器
exprnd 指数分布的随机数生成器
frnd f分布的随机数生成器
gamrnd 伽玛分布的随机数生成器
geornd 几何分布的随机数生成器
hygernd 超几何分布的随机数生成器
lognrnd 对数正态分布的随机数生成器
nbinrnd 负二项分布的随机数生成器
ncfrnd 非中心f分布的随机数生成器
nctrnd 非中心t分布的随机数生成器
ncx2rnd 非中心卡方分布的随机数生成器
normrnd 正态(高斯)分布的随机数生成器
poissrnd 泊松分布的随机数生成器
raylrnd 瑞利分布的随机数生成器
trnd 学生氏t分布的随机数生成器
unidrnd 离散均匀分布的随机数生成器
unifrnd 连续均匀分布的随机数生成器
weibrnd 威布尔分布的随机数生成器
Matlab光标变黑块的问题
现象:编辑模式下,只能改写,不能插入。
问题:键了Insert键
另外word中如何出现类似问题,
Matlab中 的accumarray函数
碰到函数accumarray是在rocwood的关于寻找完全数的程序中。没找到M文件,Document中有语法分析,没看懂。结合例子,作简单说明。
Syntax
A = accumarray(sub, val)
A = accumarray(sub, val, sz)
A = accumarray(sub, val, sz, fun)
A = accumarray(sub, val, sz, fun, fillvalue)
sub:提供累计信息的指示向量
val:提供累计数值的向量
sz:控制输出向量A的size
fun:用于计算累计后向量的函数,默认为@sum,即累加
fillvalues: 填补A中的空缺值,默认为0
Matlab的Document 里这么说:
accumarray groups elements from a data set and applies a function to each group. A = accumarray(subs,val) creates an array A by accumulating elements of the vector val using the elements of subs as indices. The position of an element in subs determines which value of vals it selects for the accumulated vector; the value of an element in subs determines the position of the accumulated vector in the output.
对于A = accumarray(subs,val)这么一个调用,有这么几个问题,理解清楚,就理解了这个函数。
例子:
val = [ 1 2 3 4 5 6]
subs = [ 1 2 4 2 4 3]' % subs是列向量
Q: accumarray总体是干嘛的?
A: 笼统的说,是用subs向量中的信息从val中提取数值做累加,累加完的结果放到A中。
Q: subs是干嘛的?
A: subs是一个累加指示向量。
subs提供的信息由两个:
(a). subs向量中的每个位置对应val的每个位置;
(b). subs中元素值相同的,val中的对应元素累加,元素值是累加完后放到A的什么地方。
如:上面的例子中,subs(2),subs(4)都是2,所以,val(2)和val(4)累加起来,放到A(2)这个位置上。
Q: val是干嘛的?
A: val是提供累加数值的,谁累加呢?就是A中的数值累加。选哪些数进行累加呢?subs向量中数值相同的对应位置的数。累加完后放到哪里呢?放到subs中指示的位置。
Q: A是怎么出来的?A的维度是什么?A的内容如何确定?
A: A的维度是subs中表示维度的数值最大的那个,如例子中size(A,1)==4,因为max(subs)==4。当然,这只是一维的情况。
最后A的结果就是:
A =
1 % subs(1)==1,所以,A(1) = val(1)。
6 % subs(2)==subs(4)==2,所以,A(2)=val(2)+val(4)
6 % subs(6)==3的值, A(3) = Val (6) = 6
8 % subs(3)==subs(5)==4,所以,A(4)=val(3)+val(5)
产生一个2*3*4的矩阵
ind = [1 1 1; 2 1 2; 2 3 4; 2 3 4];
A = accumarray(ind,11:14)
A(:,:,1) =
11 0 0
0 0 0
A(:,:,2) =
0 0 0
12 0 0
A(:,:,3) =
0 0 0
0 0 0
A(:,:,4) =
0 0 0
0 0 27
另外,关于二维和高维矩阵,只是大概知道A矩阵的维度,数值的变化不详细得知。
References:
[1] accumarray - The MathWorks http://www.mathworks.com/help/techdoc/ref/accumarray .html
[2] 向量化操作的又一重要函数accumarray的用法总结http://www.simwe.com/forum/thread-811616-1-3.html
[3] rocwood关于寻找完全数的程序
第一种:
clear;clc;close all
a=1:10000;
a(2*a'==accumarray(a',a',[],@(x)sum(a(abs(x./(1:x)-round(x./(1:x)))<eps))));
kalmanfans
搜索
日历
| 五月 | ||||||
|---|---|---|---|---|---|---|
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
| 27 | 28 | 29 | 30 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
分类
- ArcGIS
- Matlab
- Fortan
- Software application
- 爱你爱家
- Data Visualization
- Telematics Transport
- Kalman Filter, Monte Carlo, ANN
- Network Analysis
- Location Based Service LBS
- Office TOY & Funing Puzzle
- Mathematical Modeling
- 建筑 规划 设计
- 在德意志插队的日子
- Culture Philosophy
- ways to research
- 电影 音乐
- 每周一则新闻
- Bernese
- Quantum mechanics
- 数据库